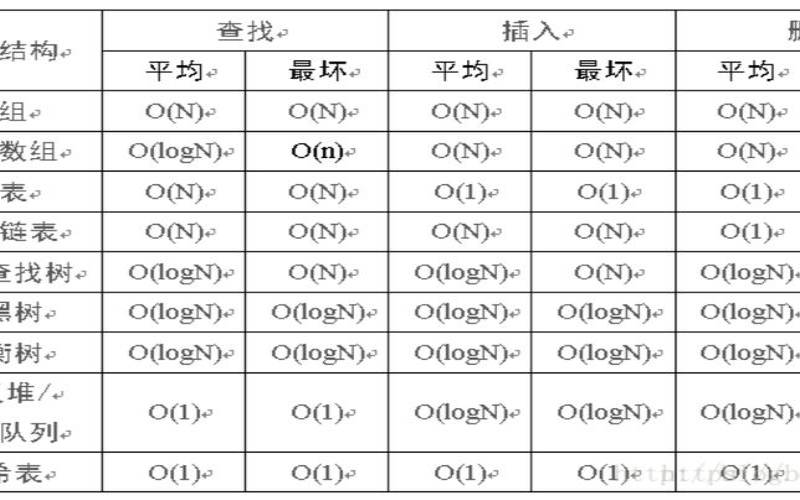

在描述算法复杂度时,经常用到**o(1),o(n),o(logn),o(nlogn)**来表示对应算法的时间复杂度,这里进行归纳一下它们代表的含义:这是算法的时空复杂度的表示。不仅仅用于表示时间复杂度,也用于表示空间复杂度。O后面的括号中有一个函数,指明某个算法的耗时/耗空间与数据增长量之间的关系。其中的n代表输入数据的量。

比如时间复杂度为O(n),就代表数据量增大几倍,耗时也增大几倍。比如常见的遍历算法。再比如时间复杂度O(n2)**,就代表数据量增大n倍时,耗时增大n的平方倍,这是比线性更高的时间复杂度。比如冒泡排序,就是典型的O(n2)的算法,对n个数排序,需要扫描n×n次。再比如O(logn)**,当数据增大n倍时,耗时增大logn倍(这里的log是以2为底的,比如,当数据增大256倍时,耗时只增大8倍,是比线性还要低的时间复杂度)。二分查找就是O(logn)的算法,每找一次排除一半的可能,256个数据中查找只要找8次就可以找到目标。**O(nlogn)**同理,就是n乘以logn,当数据增大256倍时,耗时增大256*8=2048倍。这个复杂度高于线性低于平方。归并排序就是O(nlogn)的时间复杂度。**O(1)**就是最低的时空复杂度了,也就是耗时/耗空间与输入数据大小无关,无论输入数据增大多少倍,耗时/耗空间都不变。哈希算法就是典型的O(1)时间复杂度,无论数据规模多大,都可以在一次计算后找到目标(不考虑冲突的话)
本文来源:独立服务器--o1onolognonlogn区别(log和nolog哪个好)
本文地址:https://www.idcbaba.com/duli/3095.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 1919100645@qq.com 举报,一经查实,本站将立刻删除。


