
事件管理如何发展以及人工智能(AI)如何帮助团队更聪明地工作,而不是更努力地工作。事故会给组织带来一系列问题,从临时停机到数据丢失。如果做得好,事件管理可以提供一种高效且有效的方法来修复各种事件,几乎不会造成中断,并使组织为下一次事件做好更充分的准备。
事件管理植根于IT服务台,长期以来一直是IT运营(ITOps)与最终用户之间的主要接口。随着技术的进步并变得更加复杂,组织看待事件响应的方式也随之改变。它已经远远超出了帮助用户解决问题的范围,成为保持应用程序持续正常运行和加速持续改进工作的过程。
事件管理是IT运营和DevOps团队用来响应和解决可能影响服务质量或服务运营的计划外事件的过程。事件管理旨在识别和纠正问题,同时保持正常服务并最大限度地减少对业务的影响。
公司IT运营中的事件管理(通常称为ITIL事件管理)解决了可能影响服务和业务运营的范围广泛的问题,从笔记本电脑崩溃或打印机错误到Wi-Fi连接问题和网络停机。
ITSM(IT服务管理)框架下的事件管理是ITSM服务模型的一个方面。IT的事件管理不是专注于创建系统和技术,而是更多地以用户为中心,旨在保持系统在线和运行——无论是应用程序还是端点(例如,传感器或台式计算机)。
在ITSM中,IT部门扮演着各种角色,包括解决出现的问题。这些问题的严重性是事件与服务请求的区别。简单地说,服务请求就是用户要求提供某些东西,例如建议或设备。服务可包括请求协助重置密码或为台式计算机获取额外内存。另一方面,事件更为紧急,表明存在需要解决的潜在错误。
事件是导致服务中断的单个计划外事件,而问题是服务中断的根本原因,它可以是单个事件,也可以是一系列级联事件。不同之处在于补救措施以及响应者如何解决问题。事件响应是被动的。IT部门收到警报并处理事件。在解决问题时,IT团队会找出根本原因,然后进行修复。问题管理采取积极主动的方法,查看各种类型的事件和出现的模式,以了解如何预防未来的事件。
DevOps团队专注于寻找更有效的方法来构建、测试和部署软件,这在一定程度上需要快速解决事件。与ITIL事件管理一样,DevOps事件管理旨在在不中断运营的情况下解决问题。例如,DevOps团队可能会监控较差的平均故障间隔时间(MTBF)指标,这可能表明存在需要调查的潜在问题。
由于DevOps植根于持续改进,因此非常注重事后分析和透明的无责备文化。目标是提高整体系统性能,更快地解决未来的事件,并防止未来的事件发生。与当今的IT团队一样,DevOps可以使用自动配置、事件优先级排序和支持人工智能(AI)的根本原因分析工具来确保正常运行时间,首先解决最紧迫的事件,并更快地学习如何修复和预防未来的问题。
组织通常会创建一个事件管理流程,记录响应团队应采取的事件顺序。每个人都应该知道哪些工作人员负责处理事件,解决问题所需的时间,何时将事件升级到下一个级别以及如何记录事件以及解决问题的方式。
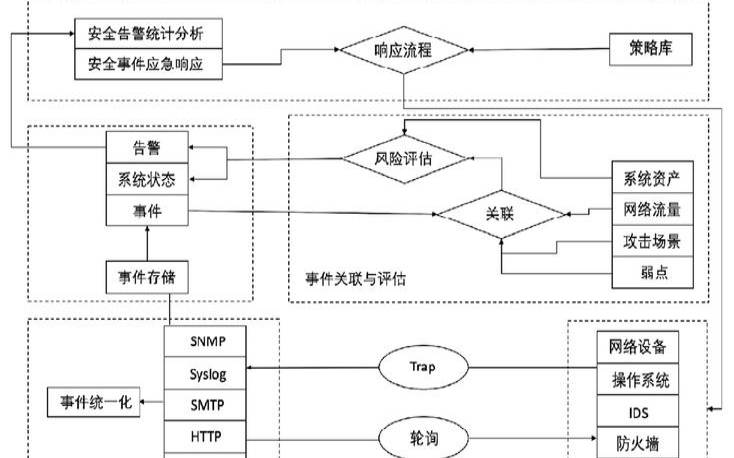
定义流程后,事件管理工作流程通常如下所示:

所有组织都需要解决问题和解决事件。这就是他们保持业务运转的方式。但拥有有效的事件解决工具和团队也有明显的好处,这些工具和团队可以在不对业务造成重大中断的情况下快速做出反应。这些好处包括:
IT运营日益复杂,部分原因是组织在日常业务运营中依赖的许多应用程序,这使得事件响应工具和自动化比以往任何时候都更加重要。
以下是一些最常见的事件管理工具:
本文来源:国外服务器--什么是事件管理(事件管理是什么意思)
本文地址:https://www.idcbaba.com/guowai/4137.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 1919100645@qq.com 举报,一经查实,本站将立刻删除。


